Regístrese ahora para una mejor cotización personalizada!































You are probably using containers for your development work (and if you aren't -you should really consider it). They behave so close to having a customized virtual machine, with almost instant-on startup that it's easy to forget they're not really virtual machines... nor should be treated as one!.
I prefer to think on container images not as a virtual machine, but as a (quite advanced) packaging system with good dependency tracking. It helps to think you're just packaging a few files... just what's needed to make your application run.
Let's have a look at some examples and try to look at our build stages with a different perspective.
I want to build my C 'Hello world' application. Since on desktop I use ubuntu, I feel more comfortable with that distribution, so my first impulse is just try to mimic my regular development environment.
This is my first attempt:
I will create an 'app' directory, add my source code there, and create my Dockerfile.
|-- Dockerfile`-- app `-- hello.c
My hello world C program:
#include <stdio.h>int main(void) { printf("Hello from the container!\n"); return (0);} In my Dockerfile, I'll do what I would do on my desktop system:
DockerfileFROM ubuntu:18.04RUN apt-get updateRUN apt-get install -y build-essentialWORKDIR /appCOPY app/hello.c /app/RUN gcc -o hello hello.cENTRYPOINT [ "/app/hello" ]
Let's build it:
$docker build -t stage0 .Step 1/7 : FROM ubuntu:18.0418.04: Pulling from library/ubuntuf22ccc0b8772: Pull complete3cf8fb62ba5f: Pull complete[... a lot of output ...]$docker run stage0 Hello from the container!
Great! We have our application working! But, let's see what happened behind the scenes.
You can see for each line in our Dockerfile, docker prints a 'Step' followed by a hash.
What is that hash? Read on to discover it...
One of the core aspects of the container images is they're based on a layered filesystem.
Let's imagine we take a snapshot of your hard drive as it is now. The hash of the filesystem contents is also noted: 29be.... on this example.

What happens when you add some files to it? (let's say your hello.c file). In the case of the filesystem of your computer, it's just added there. It's impossible to differentiate it from any other file on your hard disk.
On a layered filesystem, however, this is what you get:

You actually have two elements here:
It might not look like a big difference, but it really is!
Let's see how container images use this concept to do some magic.
Looking at our Docker build process, this is what we saw:
$docker build -t stage0 . Sending build context to Docker daemon 77.31kBStep 1/7 : FROM ubuntu:18.0418.04: Pulling from library/ubuntuf22ccc0b8772: Pull complete3cf8fb62ba5f: Pull completee80c964ece6a: Pull completeDigest: sha256:fd25e706f3dea2a5ff705dbc3353cf37f08307798f3e360a13e9385840f73fb3Status: Downloaded newer image for ubuntu:18.04---> 2c047404e52dStep 2/7 : RUN apt-get update ---> Running in a8d65ab87a93Get:1 http://archive.ubuntu.com/ubuntu bionic InRelease [242 kB]Get:2 http://security.ubuntu.com/ubuntu bionic-security InRelease [88.7 kB]...Fetched 21.8 MB in 20s (1078 kB/s)Reading package lists...Removing intermediate container a8d65ab87a93 ---> fcdd591c3bfdStep 3/7 : RUN apt-get install -y build-essential ---> Running in c15a1c650b0aReading package lists...Building dependency tree......Processing triggers for libc-bin (2.27-3ubuntu1.3) ...Removing intermediate container c15a1c650b0a ---> 9fbbc8093ab5Step 4/7 : WORKDIR /app ---> Running in fed79856ded7Removing intermediate container fed79856ded7 ---> 8bec0c4a2826Step 5/7 : COPY app/hello.c /app/ ---> 5bf5977f4128Step 6/7 : RUN gcc -o hello hello.c ---> Running in 48c0f7dc9fcbRemoving intermediate container 48c0f7dc9fcb ---> 8a99d3e111dfStep 7/7 : CMD [ "/app/hello" ] ---> Running in 2cc8c55e417bRemoving intermediate container 2cc8c55e417b---> 87a0e7eb81daSuccessfully built 87a0e7eb81daSuccessfully tagged stage0:latest$
Each time docker executes a new line in the dockerfile, it creates a new layer with the result of executing that line. It then adds that layer to the docker image, but it also keeps track of all the individual layers as cache. This process took around 2 minutes on my computer.
Looking at the images on docker now I see the image I based from (ubuntu:18.04) and my final image: 'stage0' -with the hash that I saw on the build log:87a0e7eb81da
$docker image lsREPOSITORY TAG IMAGE ID CREATED SIZEstage0 latest 87a0e7eb81da 4 minutes ago 319MBubuntu 18.04 2c047404e52d 7 weeks ago 63.3MB$
The stage0 image is made upon the following layers

docker imagewill by default hide the intermediate images, but they're indeed stored. If you run docker image ls -a, you'll see all of them:
$docker image ls -aREPOSITORY TAG IMAGE ID CREATED SIZEstage0 latest 87a0e7eb81da 4 minutes ago 319MB<none> <none> 5bf5977f4128 4 minutes ago 319MB<none> <none> 8bec0c4a2826 4 minutes ago 319MB<none> <none> 8a99d3e111df 4 minutes ago 319MB<none> <none> 9fbbc8093ab5 4 minutes ago 319MB<none> <none> fcdd591c3bfd 5 minutes ago 98.2MBubuntu 18.04 2c047404e52d 7 weeks ago 63.3MB
You can also see the size of each image: Base ubuntu is 63 Mb, that went to 98 when it executed
RUN apt-get update
and again to 319 Mb when it ran
RUN apt-get install -y build-essential
What will happen if you change the code you want to compile (your hello.c program)?
If you were deploying a virtual machine, it would mean you have to get your entire build environment again -remember you're starting from a lean ubuntu machine.
Using containers, if you change your C program and build again, this is what you get:
Hello.c#include <stdio.h>int main(void) { printf("Hello from the container! - Second version\n"); return (0);} $docker build -t stage0 .Sending build context to Docker daemon 77.31kBStep 1/7 : FROM ubuntu:18.04 ---> 2c047404e52dStep 2/7 : RUN apt-get update ---> Using cache ---> fcdd591c3bfdStep 3/7 : RUN apt-get install -y build-essential ---> Using cache ---> 9fbbc8093ab5Step 4/7 : WORKDIR /app ---> Using cache ---> 8bec0c4a2826Step 5/7 : COPY app/hello.c /app/ ---> 3853b3aff546Step 6/7 : RUN gcc -o hello hello.c ---> Running in 580c3f378281Removing intermediate container 580c3f378281 ---> 583b361ff9a2Step 7/7 : CMD [ "/app/hello" ] ---> Running in a2d18fe0c6b9Removing intermediate container a2d18fe0c6b9 ---> 8fb6676c5b38Successfully built 8fb6676c5b38Successfully tagged stage0:latest
You will notice two things:
This is because docker noticed until line 4, the result of each of the lines would be exactly the same as it has cached. How does it know it? It's tracking the layer it starts from, and the program it was run. Then it knows the result must be the same as before, so it avoids executing it and just reuses the layer that was built before.

There are a few tools that allows you to explore container images. I strongly recommend spending some time exploring your images to fully understand the magic that is going on!
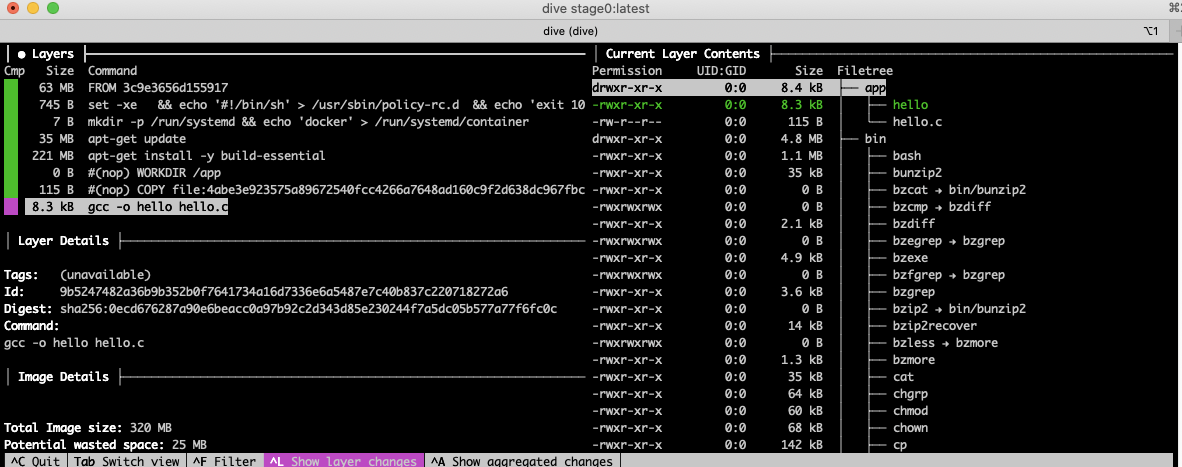
An excellent tool is Dive
This tool allows you to explore how a particular image was built, what changed on the filesystem on each of the layers, the command that was used to create a layer, etc.
Let's explore our image:
$dive stage0:latestImage Source: docker://stage0:latestFetching image... (this can take a while for large images)
There are a few important aspects here, that you will want to take into account when creating Dockerfiles:
Docker assumes that applying the same command to an image produces the same output, with the exception of COPY or ADD commands. For COPY or ADD, Docker will check the hash of the files being copied. If they are the same as used on the build generating the layer, the step is skipped and used from cache. While this works fine most of the time, it will fail if you try to get any dynamic information from the container while it's being built. For example, this Dockerfile:
FROM ubuntu:18.04WORKDIR /appRUN cp /proc/uptime /app/build_uptimeCMD ["/bin/bash", "-c", "cat /app/build_uptime"]Will generate always the same output -regardless of how many times you build it, despite the actual file content will be different.
$docker build -t uptime .Sending build context to Docker daemon 2.048kBStep 1/4 : FROM ubuntu:18.04---> 2c047404e52dStep 2/4 : WORKDIR /app---> Using cache---> 3804acc82f3cStep 3/4 : RUN cp /proc/uptime /app/build_uptime---> Using cache---> e6a794f1d69cStep 4/4 : CMD ["/bin/bash", "-c", "cat /app/build_uptime"]---> Using cache---> 00542cb52a4fSuccessfully built 00542cb52a4fSuccessfully tagged uptime:latest
$docker run uptime18946.11 111237.49$
Each new line in your Dockerfile will create a new layer -Which involves some overhead. If some commands are tightly coupled, it might make sense to put them in an unique layer. For example, instead of doing
FROM ubuntu:18.04RUN apt-get updateRUN apt-get install -y build-essentialYou might consider doing
FROM ubuntu:18.04RUN apt-get update && apt-get install -y build-essentialThis will reduce the number of layers on your image by one, but also will mean the entire layer will have to be rebuilt if anything changes.
In order to benefit from the caching, it's important the line order in your Dockerfile. For example, if instead of using
FROM ubuntu:18.04RUN apt-get updateRUN apt-get install -y build-essentialWORKDIR /appCOPY app/hello.c /app/RUN gcc -o hello hello.cCMD [ "/app/hello" ]You do
FROM ubuntu:18.04WORKDIR /appCOPY app/hello.c /app/RUN apt-get updateRUN apt-get install -y build-essentialRUN gcc -o hello hello.cCMD [ "/app/hello" ]
Each time you modify your source file, the layer at step 3 will be different -so from that point on, everything will have to be rebuilt. That means Docker will pull all the compiler files each time you change anything on your app!
All the layers created by a Dockerfile are read only -They're immutable. This is needed, so they can be reused.
But, what happens when you run a docker container and change things on the filesystem?
When you start a container, Docker takes all the layers on your image, and adds a new one on top of it -That's the read-write layer, and the one containing all the changes you do to your filesystem: File changes, file additions, file deletions.
If you delete a file on your container -you're not changing any of the image layers, you're just adding a 'note' on your read-write layer stating 'this file was deleted'.

Apart from being read-write, that is a regular layer that we can use for our own purposes. We can even create a new image with it! Let's do an experiment:
Run your application as usual, but let's give it a name so it's easier to track:
$docker run -ti --name deleting_files stage0 bash root@4c1c0ee8492b:/app#ls -ltotal 16-rwxr-xr-x 1 root root 8304 Jan 19 13:19 hello-rw-r--r-- 1 root root 115 Jan 19 13:18 hello.c
Let's delete the application and finish the container:
root@4c1c0ee8492b:/app#rm -rf *root@4c1c0ee8492b:/app#exit$
Let's start the container again -no need to give a name now.
$docker run -ti stage0 bashroot@c2c5bcdbd95e:/app#ls -ltotal 16-rwxr-xr-x 1 root root 8304 Jan 19 13:19 hello-rw-r--r-- 1 root root 115 Jan 19 13:18 hello.croot@c2c5bcdbd95e:/app#exit$
You notice the files are back there -All the deletions we did went into that read-write layer. Since our container starts from the previous layer, any modification is lost. This is what makes containers great, since you always start from a known state!.
However, that read-write layer is not lost. We can see it by doing
$docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMESc2c5bcdbd95e stage0 "bash" 2 minutes ago Exited (0) 2 minutes ago hopeful_villani4c1c0ee8492b stage0 "bash" 4 minutes ago Exited (0) 4 minutes ago deleting_files$
As you can see, if you don't give your container a name, Docker will chose a random one for you.
Having the container ID, we can make its read-write layer a regular one by using docker commit and the container id:
$docker commit c2c5bcdbd95e image_with_files_deleted sha256:f8ac6574cb8f23af018e3a998ccc9a793519a450b39ece5cbb2c55457d9a1482$
$docker image lsREPOSITORY TAG IMAGE ID CREATED SIZimage_with_files_deleted latest f8ac6574cb8f 25 seconds ago 319MB<none> <none> f1eb9f11026f 10 minutes ago 319MBstage0 latest 87a0e7eb81da 25 minutes ago 319MBubuntu 18.04 2c047404e52d 7 weeks ago 63.3MB
This is now a regular image.. so we can run a container from it:
$docker run -ti image_with_files_deleted bashroot@92dcc85d241a:/app#ls -ltotal 0root@92dcc85d241a:/app#exit
And surely, the files are not there.
Being a regular image, you could also push it to a remote repository and do FROM it in other Dockerfiles.
However, please think twice before doing so. By pushing a read-write layer you are hiding one fundamental aspect -Nobody will know how this layer was generated! While that can be sometimes useful (and we will explore it on the next post), this is not what you usually want.
On the next post, I'll dig more on how we can use layers to further optimize docker builds.
For any question or comment, please let me know in the Comments Section below, or via Twitter or Linkedin
Also check other great related content:
We'd love to hear what you think. Ask a question or leave a comment below.
And stay connected with Cisco DevNet on social!
Twitter @CiscoDevNet | Facebook | LinkedIn
Visit the new Developer Video Channel
 Etiquetas calientes:
destacado
Cisco DevNet
docker
Docker Containers
Etiquetas calientes:
destacado
Cisco DevNet
docker
Docker Containers
Regístrepor correo electrónico ahora para acciones semanales de promoción
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel en Hong Kong: 00852 66181601
Correo electrónico: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português