Regístrese ahora para una mejor cotización personalizada!





















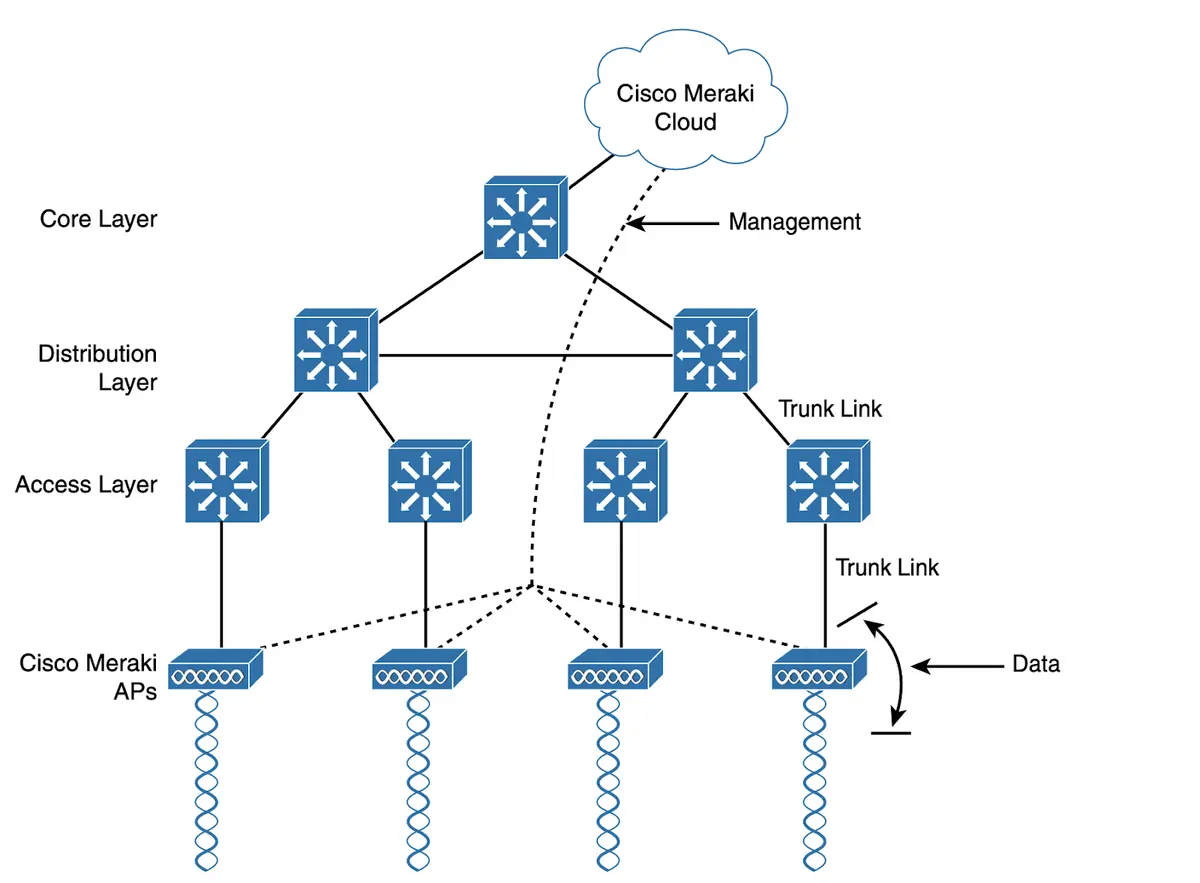



The New York Times has rejected OpenAI's claims of "hacking" in a copyright dispute, labeling them as irrelevant and untrue. The newspaper asserts that OpenAI's accusations are merely a form of attention-seeking, and it has submitted a legal response opposing OpenAI's attempt to dismiss parts of the lawsuit. OpenAI, supported by Microsoft, is accused by the Times of utilizing millions of its articles without authorization to train AI chatbots.
Alongside other copyright holders, the Times has initiated legal proceedings against tech companies for purportedly misusing their content in AI training. OpenAI responded by implying that the Times tampered with its products to replicate its content, aiming to have the copyright infringement claims dismissed. However, the Times rebuts this by stating that they only utilized initial excerpts to prompt the AI's recreation of their articles. They argue that OpenAI's real issue arises from the revelation of their extensive use of Times content, a point that OpenAI cannot contest.
The dispute between the New York Times and OpenAI highlights the complexities of legal battles in the context of emerging technologies such as AI. Furthermore, it sheds light on the need for clearer regulations and guidelines regarding using copyrighted material in AI training and development. This case could set a precedent for future disputes involving AI-generated content.
 Etiquetas calientes:
Inteligencia Artificial
Derechos de propiedad intelectual
Legal y reglament
Etiquetas calientes:
Inteligencia Artificial
Derechos de propiedad intelectual
Legal y reglament
Regístrepor correo electrónico ahora para acciones semanales de promoción
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel en Hong Kong: 00852 66181601
Correo electrónico: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

