Regístrese ahora para una mejor cotización personalizada!






















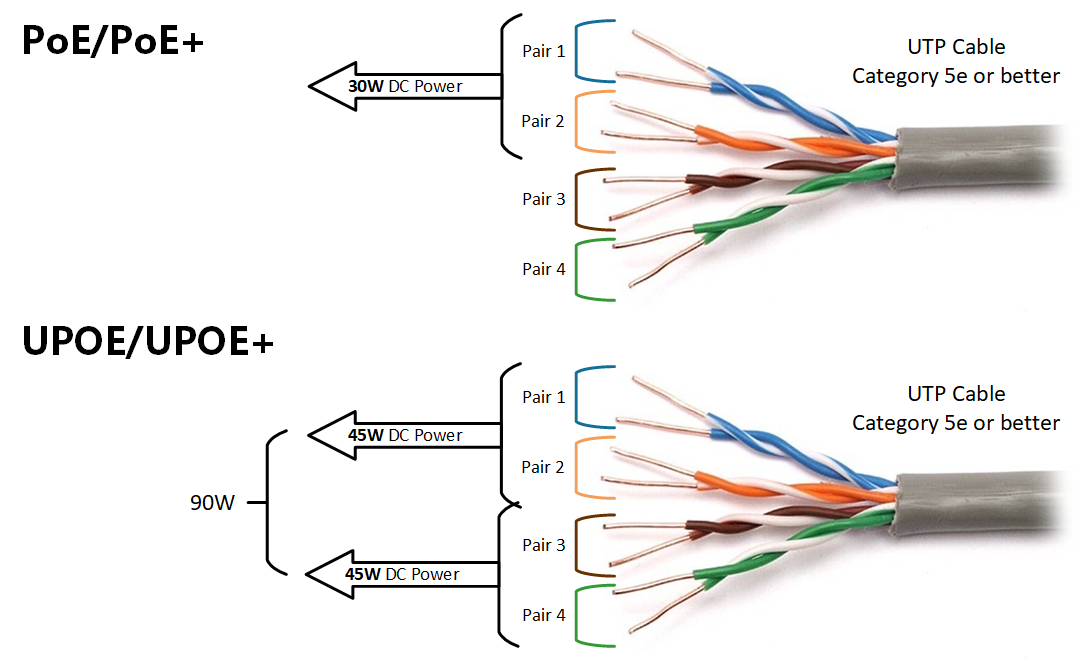






Andromeda is a cluster of 16 of Cerebras's CS-2 AI computers joined via a dedicated fabric switch and overseen by a memory machine that updates the settings of a neural network. Cerebras says programming the machine to run large language models is the beginning of a wave of clustered computing in AI.
Cerebras SystemsThe current vogue for machine learning programs that handle huge amounts of natural language input is pushing the boundaries of computing, fostering its own sort of supercomputer arms race.
Where once supercomputers were only for scientific problems, the development of AI programs known as large language models, or LLMs, is prompting businesses to seek out the same horsepower the world's top research laboratories have.
For example, Nvidia, the standard bearer in chips for AI, in September announced a cloud computing facility dedicated to large language models that will be rentable as a service by enterprises.
Monday, Cerebras Systems, the 6-year-old, Sunnyvale, Calif.-based startup that is among a gaggle of companies challenging Nvidia's dominance, unveiled a supercomputer called Andromeda that performs a quadrillion floating point math operations per second, as much as the top supercomputer in the world, Frontier, and that can achieve dramatic speed-up on tasks such as LLMs beyond the ability of thousands of GPU chips.
Also: AI could have 20% chance of sentience in 10 years, says philosopher David Chalmers
Learn about the leading tech trends the world will lean into over the next 12 months and how they will affect your life and your job.
Read nowUnlike purpose-built supercomputers that take years to assemble by system makers such as Hewlett Packard Enterprise and IBM, the Andromeda machine takes a building-block approach that makes it modular and able to be assembled in just days.
"What took them years, we stood up in three days, and what cost them$600 million, costs us less than$30 million," said Andrew Feldman, co-founder and CEO of Cerebras, comparing Andromeda to Frontier in an interview via Zoom.
Within 10 minutes of having Andromeda fully assembled, "we were able to demonstrate linear scaling without changing a line of code," said Feldman. Linear scaling means that as more individual machines are added to the cluster, the time it takes to carry out calculations drops in direct proportion.
Also: Cerebras unveils 'pay-per-model' large-model AI cloud service with Cirrascale, Jasper
For example, scientists at the Department of Energy's Argonne National Laboratory, working with the Andromeda machine in early stages, cut the time to train a large language model from 4.1 hours to 2.4 hours by doubling the number of machines from two to four.
The Andromeda machine is being presented Monday by Cerebras's Feldman at the SC22 conference, a gathering of supercomputer technologists taking place this week in Dallas, Texas. The Argonne Labs scientists are also presenting their research paper describing using the Cerebras machine.
Andromeda's cluster is a combination of Cerebras's CS-2 computers, dedicated AI machines the size of a dormitory fridge. Each CS-2 machine's chip, the Wafer-Scale-Engine, the world's largest semiconductor, has 850,000 compute cores operating in parallel fed by 40 gigabytes of fast on-chip SRAM memory.
Also: AI chip startup Cerebras nabs$250 million Series F round at over$4 billion valuation
The Andromeda cluster brings together 16 of the CS-2s for a total of 13.5 million compute cores, sixty percent more than the Frontier system. The millions of cores perform in parallel the matrix-multiply linear algebra operations necessary to transform data samples at each layer of a neural net. Each CS-2 gets a piece of the neural net training data to work on.
The CS-2s are tied together by a special data switch Cerebras introduced last year, called Swarm-X, which connects the CS-2s to a third machine, Memory-X. The Memory-X acts as a central repository for the neural "weights," or parameters, which are broadcast to each CS-2. The result of the matrix-multiply in each CS-2 is then passed back through the Swarm-X to the Memory-X as a gradient update to the weights, and the Memory-X does the work of re-computing the weights, and the cycle begins again.
Andromeda was assembled in building-block fashion by combining 16 of Cerebras's CS-2 AI computers interconnected by a switch called Swarm-X, communicating with a central coordinating computer that updates neural weights called Memory-X.
Cerebras SystemsThe Andromeda cluster is installed as a cloud-available machine by Santa Clara, California-based Colovore, which competes in the market for hosting services with the likes of Equinix.
The secret of the modular design is that the CS-2 machines can be orchestrated as a single system without the exotic parallel programing effort customarily required for a supercomputer. A maximum of 192 CS-2s can operate together at a time, and the Cerebras software takes care of the low-level functions of apportioning compute to each CS-2 and managing the weight and gradient traffic across the Swarm-X fabric.
Also:Cerebras prepares for the era of 120 trillion-parameter neural networks
"Unlike traditional supercomputers, you can send your work as if it were a single job on a single CPU," said Feldman, directly from a Jupyter notebook. "All you have to do is specify four things: what model and what parameters; how many CS-2s of the 16 you want to use; where you want the results to be sent when you're done; and how long you want the model to run for - that's it, no parallel programing, no distributed computing work."
Cerebras emphasizes the ease of clustering its CS-2s, which doesn't require writing exotic paralle, distributed programming code.
Cerebras SystemsEarly users such as the Argonne team prove the Andromeda approach can beat out some supercomputers using thousands of Nvidia GPUs, and even perform some tasks that couldn't run on the supercomputers because of memory limitations.
The Argonne research is a novel twist on large language models: a biological language model, which predicts not word combinations in sentences but biological compounds in genetic sequences. In particular, they devised a way to predict genetic sequences of variants of the SARS-CoV-2 viral DNA of COVID-19.
Using the approach of the GPT-2 large language model created by startup OpenAI, lead author Maxim Zvyagin and colleagues built a program to predict the order of the four nucleic acid bases in DNA and RNA, adenine (A), cytosine (C), guanine (G), thymine (T).
By feeding the GPT-2 program the sequences of over 110 million prokaryotic gene sequences, and then "fine-tuning" with 1.5 million different genomes of SARS-CoV-2, the program developed an ability to predict the various mutations that have appeared in variants of COVID-19.
The result is a "genome-scale language model," or GenSLM," as Zvyagin and team call their program. It can be used for viral surveillance, to anticipate the appearance of new COVID variants as a kind of early warning system.
Also:Nvidia CEO Jensen Huang announces 'Hopper' GPU availability, cloud service for large AI language models
"We propose a system that learns to model whole-genome evolution patterns using LLMs based on observed data, and enables the tracking of VOCs [variants of concern] based on measures of fitness and immune escape," they write.
The authors tested the GenSLM program on two supercomputers, the Polaris, a cluster of over two thousand Nvidia A100 GPUs; and Selene, a cluster of over 4,000 A100s. Those two machines are the number 14 and number 8 fastest supercomputers in the world. They also ran the work on Andromeda to see how it would stack up.
The Andromeda system cut the training time from over a week to days, they write:
[T]hese training runs frequently take >1 week on dedicated GPU resources (such as Polaris@ALCF). To enable training of the larger models on the full sequence length (10,240 tokens), we leveraged AI-hardware accelerators such as Cerebras CS-2, both in a stand-alone mode and as an inter-connected cluster, and obtained GenSLMs that converge in less than a day.
There is one version of the GenSLM task that could't even be run on the Polaris and Selene machines, write Zvyagin and colleagues.
A language model takes as input a certain number of letters, words or other "tokens" that are to be considered in conjunction as a sequence. In the case of natural language tasks, such as next-word prediction, a sequence five hundred or a thousand words long might be sufficient.
Also: The new Turing test: Are you human?
But genetic code, such as nucleic acid base sequences, has to be considered across thousands of tokens, known as an "open reading frame," the longest of which is 10,240 tokens. Because more input tokens take up memory on chip, the GPUs in Polaris and Selene couldn't process the 10,240-token strings for language models past a certain size because both weight memory and the input tokens exhausted the GPUs' available memory.
The market is ripe for clustered computing, says Cerebras CEO Andrew Feldman. "Large language models, we're getting to the point where people want it fast," he says. "Had we built a big cluster a year ago, everybody would have been, like, What? But right now, people are eager to train GPT-3 at thirteen billion parameters."
Cerebras Systems"We note that for the larger model sizes" of 2.5 billion neural weights or parameters, and 25 billion neural weights, "training on the 10,240 length SARS-CoV-2 data was infeasible on GPU-clusters due to out-of-memory errors during attention computation." The Andromeda machine, however, was able to handle the 10,240-token sequence because of the giant 40-gigabyte on-chip memory in each CS-2's chip using models with as many as 1.3 billion parameters.
According to Feldman, while the Argonne paper describes only two- and four-node versions of Andromeda, the presentation this week at SC22 shows the time to calculate continues to scale downward as more machines are added. The same 10.4 hours needed by a four-way Andromeda to train the GenSLM on 10,240 input tokens with 1.3 billion weights could be cut down to 2.7 hours when using all sixteen machines.
Beyond simply speed and scale, the GenSLM paper, Feldman opined, hints at something profound that is emerging in the mash-up of biological data with language models.
Also: AI's true goal may no longer be intelligence
"We put the entire COVID genome in that sequence window, and each gene we analyzed in the context of the entire genome," said Feldman.
"Why is that cool? That's cool because what we've learned over the last 30 years is that just like words, genes express themselves differently based on who their neighbors are."
From a business standpoint, said Feldman, the market is ripe for horsepower to run large language models.
"Large language models, we're getting to the point where people want itfast,"he said. "Had we built a big cluster a year ago, everybody would have been, like, What? But right now, people are eager to train GPT-3 at thirteen billion parameters, or GPT-Neo, which is a 20 billion-parameter model."
Clusters may be the cutting edge going forward for both parallel processing of a single job, and for multi-user scenarios within an organization, he suggested.
"I think there is emerging a market where people want time on a big cluster, and they want to SSH-in, they don't want anything fancy. They they just want to deliver their data and go."
 Etiquetas calientes:
Inteligencia Artificial
innovación
Etiquetas calientes:
Inteligencia Artificial
innovación
Regístrepor correo electrónico ahora para acciones semanales de promoción
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel en Hong Kong: 00852 66181601
Correo electrónico: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

